本篇文章主要介绍TF的源码结构、神经网络概述以及Keras,TFLearn高级框架
Tensorflow源码解析
Tensorflow目录结构
tensorflow-1.1.0目录:

tensorflow目录:

Tensorflow源代码学习方法
(1)了解自己要研究的基本领域,如图像分类、物体检测、语音识别等,了解对应这个领域所用的技术,如卷积神经网络 (convolutional neural network,CNN)和循环神经网络 (recurrentneural
network,RNN),知道实现的基本原理。(2)尝试运行GitHub上对应的基本模型

如果研究领域是计算机视觉,可以看代码中的如下几个目录:compresssion(图像压缩)、im2txt(图像描述)、inception(对ImageNet数据集用Inception
V3架构去训练和评估)、resnet(残差网络)、slim(图像分类)和street(路标识别或验证码识别)。
如果研究领域是自然语言处理,可以看lm_1b(语言模型)、namignizer(起名字)、swivel(使用Swivel算法转换词向量)、syntaxnet(分词和语法分析)、textsum(文本摘要)以及tutorials目录里的word2vec(词转换为向量)。
神经网络
卷积神经网络
卷积神经网络(CNN),属于人工神经网络的一种,它的权值共享 (weight sharing)的网络结构显著降低了模型的复杂度,减少了权值的数量,是目前语音分析和图像识别领域研究热点。
卷积是泛函分析中的一种积分变换的数学方法,通过两个函数f 和g 生成第三个函数的一种数学算子,表征函数f 与g 经过翻转和平移的重叠部分的面积。 ① 设f (x )和g (x )是R 1 上的两个可积函数,做积分后的新函数就称为函数f 与g
的卷积:
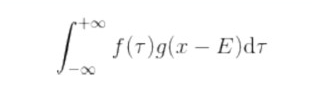
神经网络 (neural networks,NN)的基本组成包括输入层、隐藏层、输出层。卷积神经网络的特点在于隐藏层分为卷积层 和池化层 (pooling layer,又叫下采样层 )。卷积层通过一块块卷积核 (conventional
kernel)在原始图像上平移来提取特征,每一个特征就是一个特征映射;而池化层通过汇聚特征后稀疏参数来减少要学习的参数,降低网络的复杂度,池化层最常见的包括最大值池化 (max pooling)和平均值池化 (average
pooling)
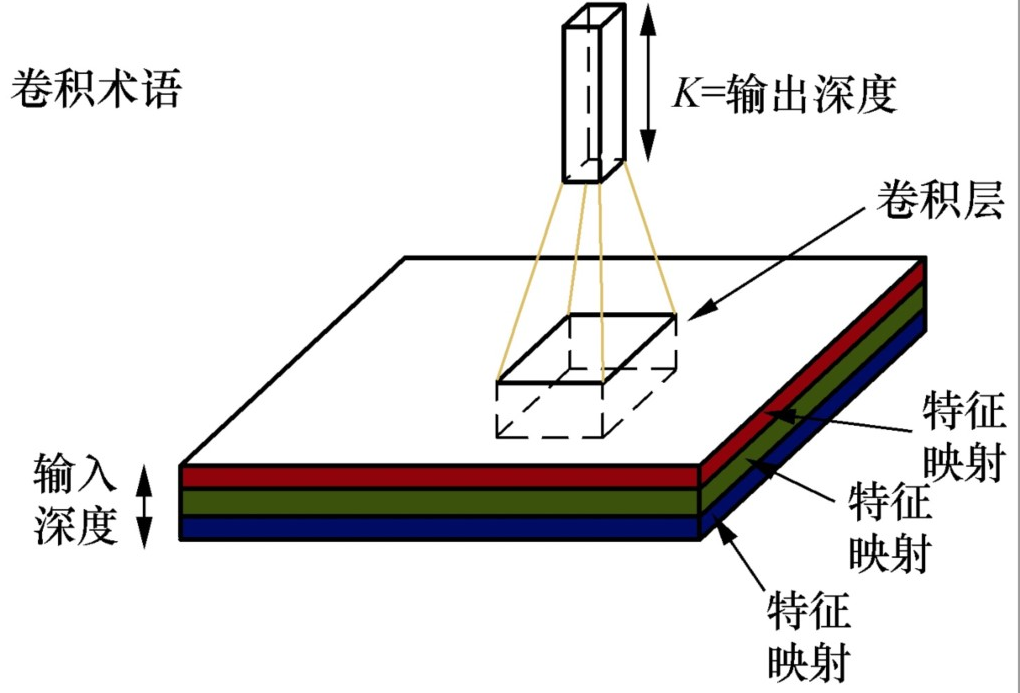
卷积核在提取特征映射时的动作称为padding,其有两种方式,即SAME和VALID。由于移动步长(Stride)不一定能整除整张图的像素宽度,我们把不越过边缘取样称为Valid
Padding,取样的面积小于输入图像的像素宽度;越过边缘取样称为Same Padding,取样的面积和输入图像的像素宽度一致。
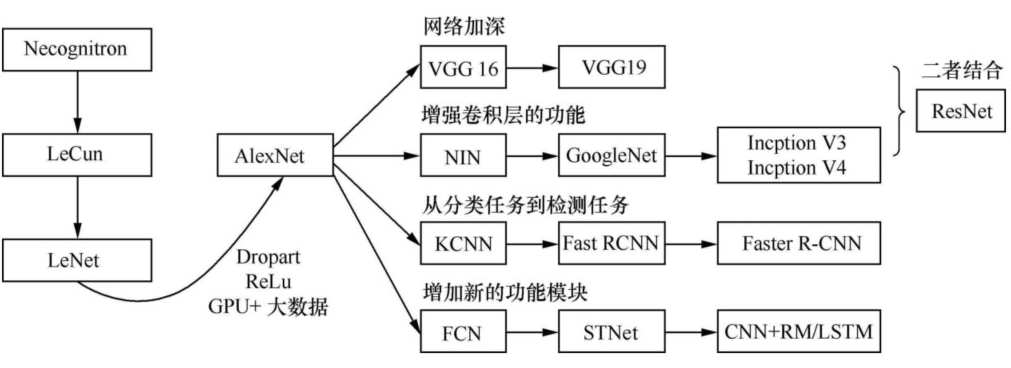
卷积神经网络发展
LeNet
LeNet的论文详见:http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
LeNet包含的组件如下。
- 输入层:32×32。
- 卷积层:3个。
- 降采样层:2个。
- 全连接层:1个。
- 输出层(高斯连接):10个类别(数字0~9的概率)。
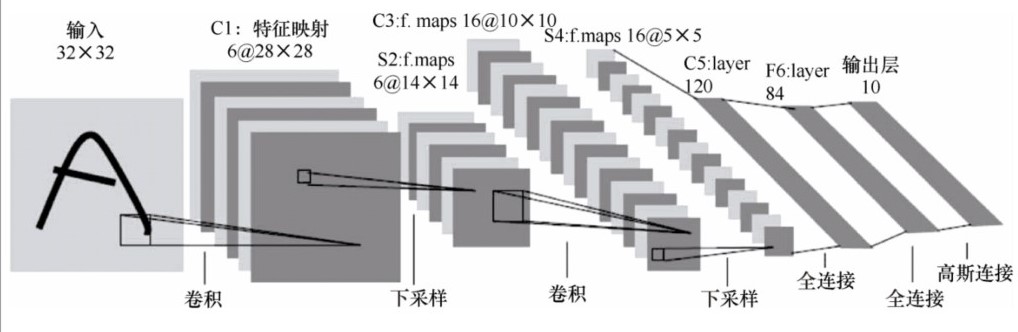
各个层的用途及意义:
(1)输入层。输入图像尺寸为32×32。这要比MNIST数据集中的字母(28×28)还大,即对图 像做了预处理reshape操作。这样做的目的是希望潜在的明显特征,如笔画断续、角点,能够出 现在最高层特征监测卷积核的中心。
(2)卷积层(C1, C3, C5)。卷积运算的主要目的是使原信号特征增强,并且降低噪音。在一 个可视化的在线演示示例 [5] 中,我们可以看出不同的卷积核输出特征映射的不同,如图 6-5 所示。
(3)下采样层(S2, S4)。下采样层主要是想降低网络训练参数及模型的过拟合程度。通常 有以下两种方式。
- 最大池化 (max pooling):在选中区域中找最大的值作为采样后的值。
- 平均值池化 (mean pooling):把选中的区域中的平均值作为采样后的值。
(4)全连接层(F6)。F6是全连接层,计算输入向量和权重向量的点积,再加上一个偏置。 随后将其传递给sigmoid函数,产生单元i 的一个状态。
(5)输出层。输出层由欧式径向基函数 (Euclidean radial basis function)单元组成,每个类 别(数字的0~9)对应一个径向基函数单元,每个单元有84个输入。也就是说,每个输出RBF单
元计算输入向量和该类别标记向量之间的欧式距离。距离越远,RBF输出越大。
AlexNet
AlexNet的论文详见Alex Krizhevsky、Ilya Sutskever和Geoffrey E.Hinton的《ImageNet Classification with Deep Convolutional Neural
Networks》
AlexNet由5个卷积层、5个池化层、3个全连接层,大约5000万个可调参数组成。最后一个全连接层的输出被送到一个1000维的softmax层,产生一个覆盖1000类标记的分布。AlexNet由两个GPU协作:一个GPU运行图中顶部的层次部分,另一个GPU运行图中底部的层次部分。GPU之间仅在某些层互相通信。
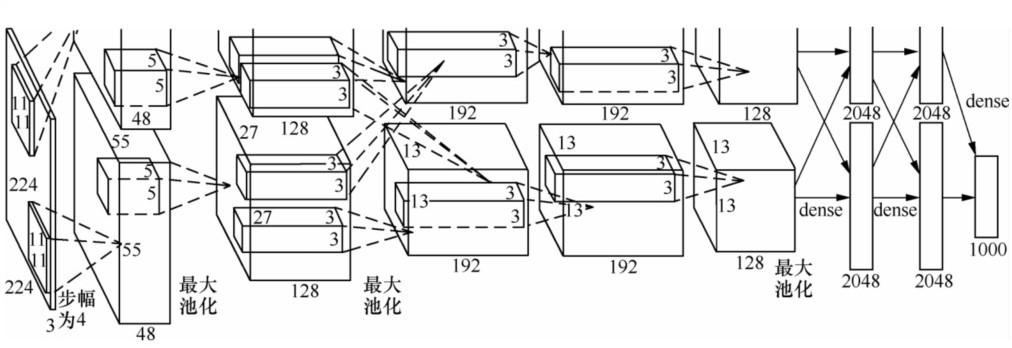
特点:
- 防止过拟合:Dropout、数据增强 (data augmentation)。
- 非线性激活函数:ReLU。
- 大数据训练:120万(百万级)ImageNet图像数据。
- GPU实现、LRN(local responce normalization)规范化层的使用。
Dropout。AlexNet做的是以0.5的概率将每个隐层神经元的输出设置为0。以这种方式被抑制的神经元既不参与前向传播,也不参与反向传播。因此,每次输入一个样本,就相当于该神经网络尝试了一个新结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他神经元而存在,所以这种技术降低了神经元复杂的互适应关系。因此,网络需要被迫学习更为健壮的特征,这些特征在结合其他神经元的一些不同随机子集时很有用。如果没有Dropout,我们的网络会表现出大量的过拟合。Dropout使收敛所需的迭代次数大致增加了一倍。
VGGNet
VGGNet可以看成是加深版本的AlexNet,参见Karen Simonyan和Andrew Zisserman 的论文《Very Deep Convolutional Networks for Large-Scale Visual
Recognition》
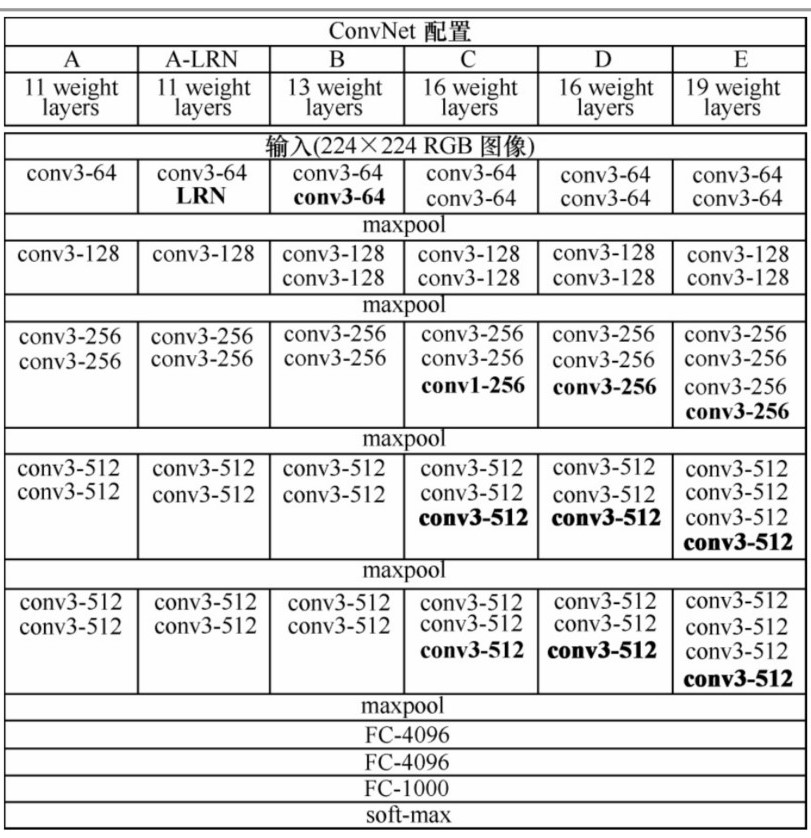
VGGNet也是5个卷积组、2层全连接图像特征、1层全连接分类特征,可以看作和AlexNet一样总共8个部分。根据前5个卷积组,VGGNet论文中给出了A~E这5种配置。卷积层数从8(A配置)到16(E配置)递增。VGGNet不同于AlexNet的地方是:VGGNet使用的层更多,通常有16~19层,而AlexNet只有8层。
GoogLeNet
GoogLeNet的更多内容详见Christian Szegedy和Wei Liu等人的论文《Going Deeper with Convolutions》
NIN(Network in Network)(详见Min Lin和Qiang Chen和Shuicheng Yan的论文《Network In Network》),它对传统的卷积方法做了两点改进:将原来的线性卷积层(linear convolution layer)变为多层感知卷积层(multilayer perceptron);将全连接层的改进为全局平均池化。
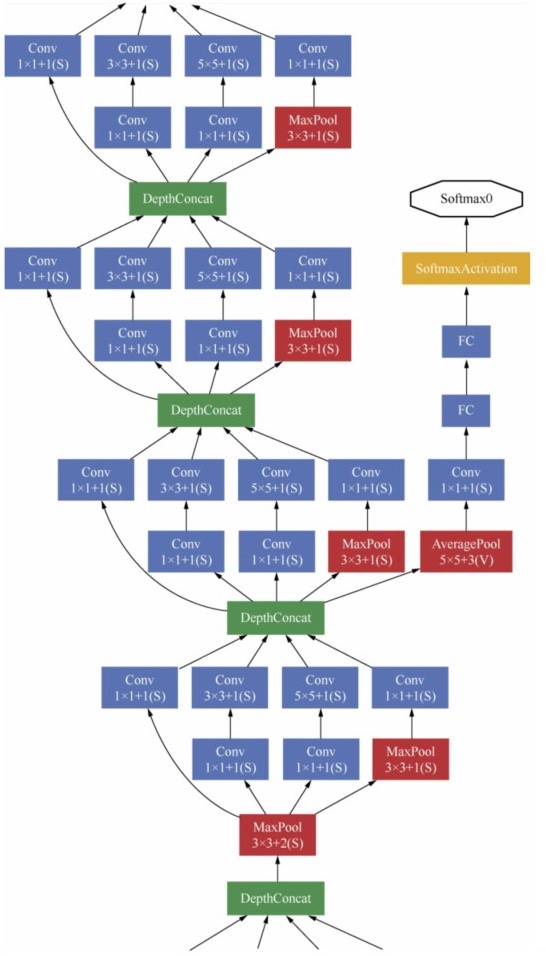
GoogLeNet的主要思想是围绕“深度”和“宽度”去实现的。
(1)深度。层数更深,论文中采用了22层。为了避免梯度消失问题,GoogLeNet巧妙地在不同深度处增加了两个损失函数来避免反向传播时梯度消失的现象。
(2)宽度。增加了多种大小的卷积核,如1×1、3×3、5×5,但并没有将这些全都用在特征映射上,都结合起来的特征映射厚度将会很大。但是采用了图6-11右侧所示的降维的Inception模型,在3×3、5×5卷积前,和最大池化后都分别加上了1×1的卷积核,起到了降低特征映射厚度的作用。
ResNet
残差网络的更多内容详见Kaiming He、Xiangyu Zhang、Shaoqing Ren和Jian Sun的论文《Deep Residual Learningfor Image Recognition》
循环神经网络
循环神经网络主要是自然语言处理(natural language
processing,NLP)应用的一种网络模型。循环神经网络的特点在于它是按时间顺序展开的,下一步会受本步处理的影响。循环神经网络的解决方式是,隐藏层的输入不仅包括上一层的输出,还包括上一时刻该隐藏层的输出。理论上,循环神经网络能够包含前面的任意多个时刻的状态,但实践中,为了降低训练的复杂性,一般只处理前面几个状态的输出。
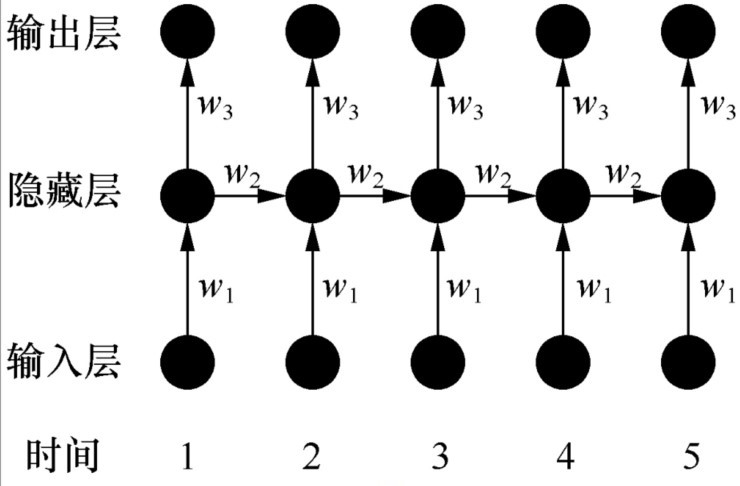
循环神经网络的训练也是使用误差反向传播 (backpropagation,BP)算法,并且参数w1、w2和w3是共享的。但是,其在反向传播中,不仅依赖当前层的网络,还依赖前面若干层的网络,这种算法称为随时间反向传播
(backpropagation through time,BPTT)算法。BPTT算法是BP算法的扩展,可以将加载在网络上的时序信号按层展开,这样就使得前馈神经网络的静态网络转化为动态网络。
循环神经网络发展
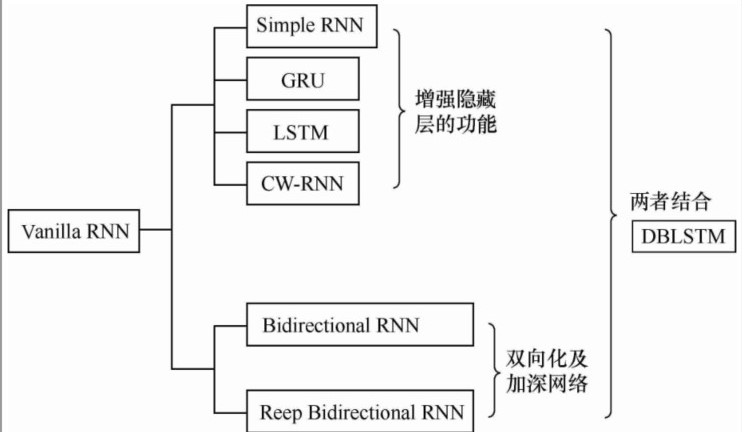
Tensorflow高级框架
TFLearn
1.加载数据
1 | import tflearn |
2.构建网络模型
1 | # 构建AlexNet网络 |
3.训练模型
1 | model = tflearn.DNN(network, checkpoint_path='model_alexnet', |
Keras
特点:
模块化 :模型的各个部分,如神经层、成本函数、优化器、初始化、激活函数、规范化都是独立的模块,可以组合在一起来创建模型。
极简主义 :每个模块都保持简短和简单。
易扩展性 :很容易添加新模块,因此Keras适于做进一步的高级研究。
使用Python语言:模型用Python实现,非常易于调试和扩展。
Keras的核心数据结构是模型。模型是用来组织网络层的方式。模型有两种,一种叫Sequential模型,另一种叫Model模型。
Sequential模型是一系列网络层按顺序构成的栈,是单输入和单输出的,层与层之间只有相邻关系,是最简单的一种模型。
Model模型是用来建立更复杂的模型的。
1 | # Sequential模型的使用 |

