pandas
Pandas 是python的一个数据分析包,最初由AQR Capital
Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为**
时间序列分析**提供了很好的支持。
Pandas官网:https://pandas.pydata.org/
Pandas源码:https://github.com/pandas-dev/pandas.git
数据结构
- Series:
一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series如今能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。对于一个Series,其中最常用的属性为值(values),索引(index),名字(name),类型(dtype)。我们用s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'],name='这是一个Series',dtype='float64')
这样的方式来创建一个Series。并使用s.values;s.index;s.name;s.dtype
来访问Series的属性。同时Series可以调用相当多的方法,会保留NumPy的数组操作(用布尔数组过滤数据,标量乘法,以及使用数学函数),并同时保持引用的使用 - Time- Series:以时间为索引的Series。
- DataFrame
:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。我们用df = pd.DataFrame({'col1':list('abcde'),'col2':range(5,10),'col3':[1.3,2.5,3.6,4.6,5.8]},index=list('一二三四五'))
来创建一个DataFrame。DataFrame取出一列变成Series - Panel :三维的数组,可以理解为DataFrame的容器。
- Panel4D:是像Panel一样的4维数据容器。
- PanelND:拥有factory集合,可以创建像Panel4D一样N维命名容器的模块。
文件的读取,写入
pandas支持csv格式,txt格式,xls格式等诸多数据文件的读写。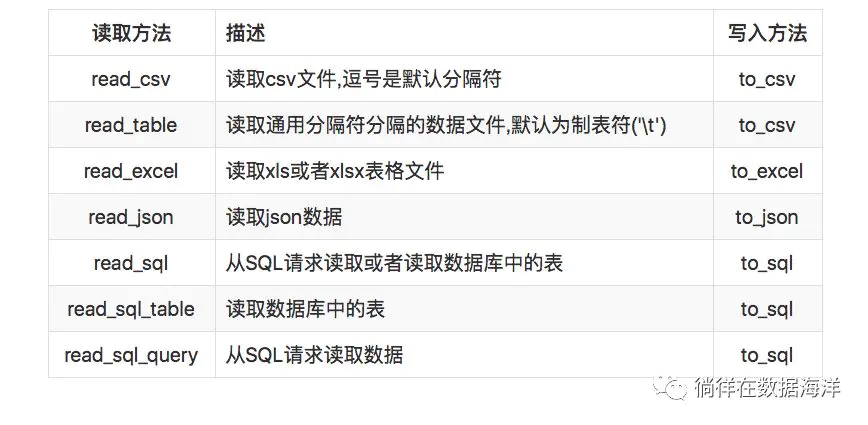
在此注重介绍csv格式的读取。
pandas.read_csv
pandas.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]], sep=’,’, delimiter=None, header=’infer’,
names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None,
converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None,
na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False,
infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False,
chunksize=None, compression=’infer’, thousands=None, decimal: str = ‘.’, lineterminator=None, quotechar=’”‘, quoting=0,
doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True,
delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
这个函数参数太多,我第一眼看见的时候也是吓了一跳。不过在实际使用时,大家也只是用df=pandas.read_csv('XXX.csv')使用第一个参数(filepath_or_buffer)
:任何有效的字符串路径都是可以接受的,也可以是URL。
其他请访问官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
基本函数
在平时的数据处理中下列函数被大量的使用,提前整理如下:
head和tail
DataFrame.head(self:〜FrameOrSeries,n:int = 5 ) →〜FrameOrSeries
此函数根据位置返回对象的前n行。这对于快速测试对象中的数据类型是否正确非常有用。
对于n的负值,此函数返回除最后n行之外的所有行,等效于df[:-n]
DataFrame.tail(self: ~FrameOrSeries, n: int = 5) → ~FrameOrSeries
此函数与head大同小异,只是返回数据后n列。
对于n的负值,此函数返回除最前n行之外的所有行,等效于df[n:]
unique和nunique
DataFrame.nunique(self, axis=0, dropna=True) → pandas.core.series.Series
axis:要使用的axis。行为0或’index’,列为1或’columns’。
dropna bool:默认为True,是否将NaN包括在内。
该函数返回有多少个唯一值。
Series.unique(self)
该函数返回Series对象的唯一值
count和value_counts
DataFrame.count(self, axis=0, level=None, numeric_only=False)
axis:{0或’index’,1或’columns’},默认0。如果为0或“索引”,则为每列生成计数 s。如果为1或“列”,则为每行生成计数 s 。
level:int或str,可选。如果axis是MultiIndex(分层,有多个索引),则沿特定级别计数,并折叠为DataFrame。一个str指定级别名称。
该函数返回非缺失值元素个数。
Series.value_counts(self, normalize=False, sort=True, ascending=False, bins=None, dropna=True)
normalize boolean:将normalize设置为True时,通过将所有值除以值的总和来返回相对频率。
bins int:可选。不是对值进行计数,而是将它们分组到半开箱中,便于在pd.cut帮助下处理数据。
该函数返回一个包含唯一值计数的Series。
describe和info
DataFrame.describe(self: ~FrameOrSeries, percentiles=None, include=None, exclude=None) → ~FrameOrSeries
percentiles:类似于数字的列表,可选。要包含在输出中的百分比。所有值都应介于0和1之间。默认值为 ,它返回第25、50和75个百分位数。[.25, .5, .75]
include :“all”,类似dtype的列表或无(默认),可选。要包括在结果中的数据类型的白名单。忽略Series。
以下是include选项:
‘all’:输入的所有列将包含在输出中。
类似于dtypes的列表:将结果限制为提供的数据类型。要将结果限制为数字类型,请提交 numpy.number。要将其限制为对象列,请提交numpy.object数据类型。字符串也可以select_dtypes(例如)的样式使用
。要选择熊猫分类列,请使用df.describe(include=[‘O’])’category’None(默认):结果将包括所有数字列
Notes:
对于数字数据,则结果的指数将包括count, mean,std,min,max以及下,50和上百分。默认情况下,较低的百分比是25,较高的百分比是75。该50百分比是一样的中位数。
为对象的数据(例如字符串或时间戳),则结果的指数将包括count,unique,top,和freq。该top 是最常见的值。该freq是最常见的值的频率。时间戳记还包括first和last项目。
如果多个对象值具有最高的计数,则将 从具有最高计数的那些中任意选择count和top结果。
对于通过提供的混合数据类型DataFrame,默认值为仅返回对数字列的分析。如果数据框仅由对象和类别数据组成,而没有任何数字列,则默认值为返回对对象和类别列的分析。如果include=’all’作为选项提供,则结果将包括每种类型的属性的并集。
DataFrame.info(self, verbose=None, buf=None, max_cols=None, memory_usage=None, null_counts=None) → None
此方法打印信息息有关包括索引D型和列dtypes,非空值和存储器使用量的数据帧。
verbose boolean 是否打印完整的摘要。
buf 可写缓冲区,默认为sys.stdout。将输出发送到哪里。默认情况下,输出将打印到sys.stdout。如果需要进一步处理输出,请传递可写缓冲区。
memory_usage bool,str,可选。指定是否应显示DataFrame元素(包括索引)的总内存使用情况。True始终显示内存使用情况。False永远不会显示内存使用情况。“
deep”的值等效于“真正的内省”。内存使用情况以可读单位(以2为基数的表示形式)显示。null_counts bool,可选。是否显示非空计数。默认情况下,仅当框架小等于时显示。值为True始终显示计数,而值为False则不显示计数。

